Istnieje sporo czynników wpływających na pozycjonowanie serwisu internetowego, lecz bez wątpienia dobrze przemyślana architektura informacji (w uproszczeniu – podział treści, zasobów, informacji na podstrony) stanowi fundament dla wszelkich dalszych działań optymalizacyjnych i pozycjonerskich. Z artykułu dowiesz się, jak poprawnie planować architekturę informacji.
Content
Jak planować architekturę informacji?
Aby poprawnie zaplanować architekturę informacji w kontekście późniejszego pozycjonowania (a przy okazji także UX), należy zastanowić się, do kogo i z jakimi zasobami chcemy dotrzeć. Odwracając to – należy zastanowić się, w odpowiedzi na jakie słowa kluczowe chcemy pojawiać się w wynikach wyszukiwania. Aby architektura informacji umożliwiała efektywne pozyskiwanie ruchu z Google należy pamiętać o kilku zasadach:
- Każdemu tematowi (reprezentowanemu przez frazę lub zestaw fraz bliskoznacznych) należy poświęcić osobną podstronę.
- Nie należy tworzyć wiele podstron na ten sam temat (targetujących te same frazy).
- W tworzeniu struktury strony należy zachować odpowiednią hierarchię – od ogółu do szczegółu.
- Każda podstrona powinna być podlinkowana wewnętrznie – innymi słowy, do każdej podstrony musi dać się „doklikać” za pomocą linków
- Dla każdej wydzielonej strony należy przygotować unikalną treść dobrze pokrywającą wybrany temat.
W zasadzie, można powiedzieć, że to tyle. W praktyce jednak czeka na nas szereg zagrożeń i pułapek.
Błędy w architekturze informacji
Reguła działa w dwie strony. Skoro poprawnie zaplanowana architektura informacji stanowi fundament dla SEO, to źle zaplanowana i wdrożona struktura uniemożliwi efektywne zdobywanie ruchu. Poniżej opisuję najczęstsze błędy popełniane w planowaniu architektury informacji w kontekście SEO.
Zbyt ogólne i trudne frazy w strukturze strony
Jeśli twoja strona będzie zbyt ogólna, to ciężko będzie ci zdobyć wysokie pozycje. Jeśli przykładowo zatytułujesz daną podstronę „Opony”, to choćbyś napisał bardzo wartościowy artykuł, niezmiernie ciężko będzie zdobyć ruch z tej frazy. Po prostu konkurencja jest zbyt ciężko. Nawet nie chodzi o to, że treści konkurencyjnych jest dużo. Chodzi o to, że wielkie serwisy z wyrobionym autorytetem (mocnym profile linków pozycjonujących) takie jak Wikipedia, duże sklepy internetowe, serwisy aukcyjne i porównywarki albo portale newsowe, już z pewnością zajmują pierwszych kilkanaście lub kilkadziesiąt pozycji. Pamiętaj, że praktycznie tylko top10 (pierwsza strona wyników) daje ruch. W przypadku niektórych zapytań mogą to być nawet top5 lub top3, gdy ruch płynie głównie z mobile, a strona wyników w Google najeżona jest reklamami i widgetami mającymi za zadanie zatrzymać użytkownika w widoku wyszukiwarki. Mierz siły na zamiary. Przynajmniej rozpoczynając przygodę z SEO.
Strony na tematy, których nikt nie szuka
Z pustego i Salomon nie naleje. Jeśli stworzysz sporo stron, które poświęcone są bardzo szczegółowym kwestiom, których nikt nie szuka, nie przełoży się to na ruch. Oczywiście możesz podjąć działania reklamowe mające na celu ściągnięcie ruchu, ale nie będzie to ruch z Google. SEO to element inbound marketingu, gdzie to użytkownik zgłasza zapotrzebowanie na określoną informację czy zasób, a wyszukiwarka odpowiada mu najbardziej dopasowanymi wynikami. Jeśli twoim celem jest pozyskiwać ruch z wyszukiwarki, najpierw poznaj stronę popytową – zobacz, czego szukają użytkownicy. Jak to zrobić? Dowiesz się z dalszej części tekstu.
Strony targetujące te same lub podobne frazy – kanibalizacja
Bardzo powszechnym problemem jest powielanie tych samych zagadnień na wielu stronach. Oczywiście w 100% tego nie unikniemy. Na przykład na moim blogu słowa pozycjonowanie, audyt, czy po prostu SEO pojawiają się praktycznie na każdym kroku. Unikam jednak sytuacji, w której dane słowo kluczowe (to, na które chcę wyskakiwać w Google) byłoby szczególnie wyeksponowane na wielu podstronach – np. w tytule artykułów. Kanibalizacja w przypadku sklepów internetowych pojawia się często między stronami wielu podobnych produktów. Dlatego trzeba dobrze się zastanowić, jak wydzielić grupy produktowe. Wyobraź sobie dany model obuwia – np. Adidas Superstar Originals, takie białe, klasyczne. Zazwyczaj na stronie produktu mamy możliwość wybrania rozmiaru, który nas interesuje. Gdyby jednak projektant strony stwierdził, że każdy rozmiar będzie miał osobną podstronę, to wówczas odpowiedzią na hasło Adidas superstar originals byłyby podstrony: /adidas-superstar-originals-37 /adidas-superstar-originals-38 /adidas-superstar-originals-39 /adidas-superstar-originals-40 /adidas-superstar-originals-41 … i wiele kolejnych W efekcie Google nie wiedziałoby, która podstrona stanowi właściwą odpowiedź na to istotne słowo kluczowe. Google widząc taką sytuację dokona wyboru arbitralnie, nie zawsze z korzyścią dla nas. Często też nasza domena nie osiągnie maksymalnej pozycji, która byłaby możliwa przy optymalnej architekturze informacji. Sprawa bywa w niektórych segmentach problematyczna, bo tych samych fraz może dotyczyć strona kategorii, produktu, czy też marki.
Dlatego też trzeba zachowywać odpowiednią hierarchię (strony ogólne – grupujące produktu w odpowiednie zbiory, a pod nimi bardziej szczegółowe – strony konkretnych produktów). Kanibalizować się też mogą kolekcje damskie i męskie, jeśli struktura nie jest dobrze podzielona i opisana (np. tu i tu tytuł brzmi po prostu Kurtki zimowe). Czasem na poziomie produktów nie da się uniknąć kanibalizacji w 100%. Wówczas z pomocą mogą przyjść linki kanoniczne (to już trochę wyższa szkoła jazdy, https://support.google.com/webmasters/answer/139066?hl=pl) oraz próby targetowania tejże powtarzającej się frazy za pomocą strony jednoznacznie mocniejszej – nadrzędnej kategorii. Z kanibalizacją wynikającą z niewłaściwego zarządzania architekturą spotykam się też bardzo często na blogach.
Domyślna struktura strony opartej na popularnym CMS WordPress wymusza niejako stosowanie kategorii, które dzielą artykuły na osobne listingi. Oczywiście możemy mieć jedną kategorię. Nikt nam nie zabroni. Jednak każda kategoria to osobna strona z unikalną mieszanką treści, która może stanowić stronę docelową. Jeśli masz blog parentingowy, to możesz wydzielić sobie kategorie Podróże z dziećmi, Przepisy dietetyczne dla dzieci i na przykład Recenzje bajek i dzięki temu docierać do osób szukających właśnie tych zagadnień. Z drugiej strony istnieje też zagrożenie, że będziesz targetować te same frazy przez stworzenie artykułu takiego jak nazwa kategorii. Na przykład masz wspomnianą kategorię Podróże z dziećmi, w obrębie której publikujesz artykuły na różne tematy podróżniczo-parentingowe, ale dodatkowo tworzysz artykuł Podróże z dziećmi – przewodnik od A do Z.
Wówczas na hasło „podróże z dziećmi” masz już dwie osobne podstrony. Jeśli do tego używasz nierozmyślnie tagów (taksonomii /tag/) możesz np. stworzyć (zapewne w dobrej wierze, chociaż to bez sensu) tagi podróżowanie z dziećmi, dzieci w podróży itp. To niestety częsty błąd. Unikaj też tworzenia serii wpisów opartych na tym samym tytule: Jak się modnie ubrać cz. I Jak się modnie ubrać cz. II Jak się modnie ubrać cz. III Jeśli tworzysz cykl, to zatytułuj go w jakiś bardziej ogólny sposób, a poszczególne części podziel w sposób jednoznaczny. Przykładowo – nazwa cyklu: Jak się modnie ubrać? – robisz wstęp opisujący zagadnienie bardzo ogólnie, a następnie tworzysz listę z linkami do kolejno publikowanych artykułów; np.: Wpis1: Jak dobierać ubrania do właściwej okazji Wpis2: Jak łączyć ze sobą kolory, aby wyglądać dobrze Wpis3: … Widzisz jak wiele kombinacji może powstać w przypadku sklepu internetowego, który ma dodatkowo moduł blogowy? 🙂
Brak logicznej hierarchii w architekturze informacji
W kontekście hierarchii dobrze jest dzielić stronę na logiczne podzbiory. Nazwij stronę główną w jakiś deskryptywny sposób. Czym jest twoja strona? W przypadku e-commerce:
- sklep obuwniczy online
- sklep wędkarski
- sklep z wyposażeniem wnętrz
- sklep internetowy dla alpinistów
W przypadku bloga:
- blog podróżniczy
- blog parentingowy
- blog o…
- blog dla…
- blog podróżniczy o…
- blog modowy dla…
Następnie wydzielasz najbardziej ogólne zbiory – zwykle strony kategorii. W sklepie internetowym z butami sportowymi np. może to być klasyfikacja ze względu na dyscypliny:
- buty do biegania
- buty rowerowe
- buty trekkingowe
- buty do tenisa
- …
Na blogu będą to kategorie zagadnień, o których piszesz. Na przykład na blogu literackim:
- recenzje książek kryminalnych
- recenzje thrillerów
- biografie pisarzy
- …
Następnym elementem będą już właściwe strony z treścią, której szuka użytkownik – strony produktów lub artykuły. Oczywiście w niektórych przypadkach może być konieczne stworzenie dodatkowych stopni struktury (kolejnych poziomów – podkategorii). Konieczne może być też zastosowanie innych sposobów klasyfikacji treści (tu można wykorzystać inną taksonomię, np. tagi). Wyobraź sobie serwis z informacjami o samochodach. Menu główne może być oparte na podziale wg marek, ale osobno możesz stworzyć listingi z klucza kraju pochodzenia lub klasy, zastosowania (sportowe, rodzinne, terenowe etc.).
Sierotki – orphan pages
Google musi widzieć serwis jako całość – zbiór połączonych ze sobą podstron. W ten sposób mapuje strukturę serwisu, uczy się zależności między poszczególnymi pojęciami, tematami. Dla każdej strony wyliczana jest też ocena, która zależy między innymi od tego, jak wiele innych stron do niej linkuje (wskazuje, że jest ważna). Jeśli dana podstrona w ogóle nie jest podlinkowana wewnętrznie, to może dojść do sytuacji, w której Google w ogóle jej nie znajdzie, a nawet jeśli do niej dotrze, to ze względu na brak autorytetu, nie będzie jej wyświetlać wysoko.
Thin content
Google nie może sobie pozwolić na odsyłanie użytkownika do stron, które go rozczarują. To by oznaczało, że jako wyszukiwarka zawiedli. Dlatego algorytm każdorazowo ocenia, czy strony docelowe są bogate we właściwe informacje. W szczególności, czy posiadają treści tekstowe pokrywające dany temat. Nie ma reguły mówiącej, ile tekstu powinno być na stronie docelowej, aby nie została uznana za stronę bez jakościowej treści (thin content). Warto patrzeć tu przez pryzmat konkurencji w top10. Pamiętajmy, że dla zapytań słownikowych wymaganej (i adekwatnej) treści będzie dużo mniej niż np. dla hasła historia wojny secesyjnej. Na pewno jednak warto zadbać, aby na każdej stronie docelowej pojawił się blok tekstu, który informuje o funkcji strony (np. opis kategorii w sklepie internetowym mówiący o tym, jaki znajduje się w niej asortyment, jakie znajdzie zastosowania, dla kogo jest przeznaczony). Pamiętaj też, że wiele podstron pojawia się automatycznie w ramach domyślnej konfiguracji danego silnika strony. Na przykład na WordPress domyślnie tworzyć i indeksować się będą podstrony załączników (czyli strony zawierające w swojej treści oprócz nagłówka i stopki tylko plik graficzny z bazy dodanych mediów).
Skąd brać informacje o słowach kluczowych do planowania struktury
Na koniec kilka słów o tym, skąd w ogóle czerpać informacje o słowach kluczowych. Jak już wcześniej powiedziałem, warto sprawdzić, czego realnie szukają użytkownicy. W tym celu należy skorzystać z odpowiedniego oprogramowania – np. Senuto, Semstorm albo planera słów kluczowych Google (trzeba opłacić kampanię Google Ads, aby mieć dostęp do sensownych danych). Za darmo ciężko będzie zebrać te dane. Programy takie jak Senuto mają zwykle trial, który niektórym może wystarczyć. W przypadku konkurencyjnych branż i dużych serwisów (specjalistyczne serwisy wiedzowe, sklepy internetowe) konieczna jednak będzie z pewnością bardziej szczegółowa i długofalowa analiza. Do zbierania informacji o słowach kluczowych można podejść na kilka sposobów
Słowa kluczowe wpisane z palca, na wyczucie
Można po prostu odpytać narzędzie o konkretne, podane przez nas słowa kluczowe:  Wówczas Senuto pokazuje nam konkretne statystyki dla wskazanych haseł (o ile posiada te dane – frazy są wyszukiwane i znajdują się w bazie):
Wówczas Senuto pokazuje nam konkretne statystyki dla wskazanych haseł (o ile posiada te dane – frazy są wyszukiwane i znajdują się w bazie): 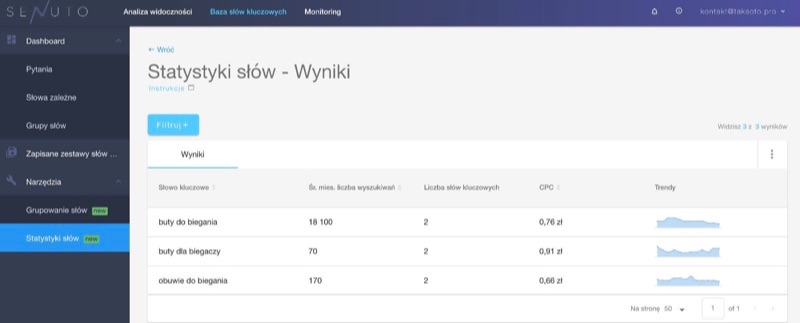
Frazy z grupy tematycznej
Możemy też pozwolić narzędziom na podpowiadanie nam poszczególnych słów powiązanych z zadanym hasłem. W Senuto to po prostu domyślny sposób działania bazy słów kluczowych. Wyniki dostaniemy posortowane z klucza liczby wyszukiwań, czyli popularności danego hasła: 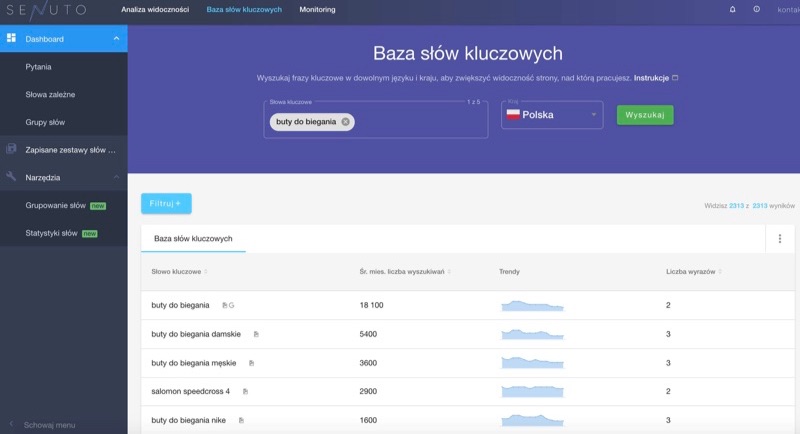 Jak widać po powyższym screenie dostajemy tutaj hasła, które mogą w ogóle nie zawierać zadanego ciągu znaków (np. w wynikach dla zapytania buty do biegania dostajemy salomon speedcross 4).
Jak widać po powyższym screenie dostajemy tutaj hasła, które mogą w ogóle nie zawierać zadanego ciągu znaków (np. w wynikach dla zapytania buty do biegania dostajemy salomon speedcross 4).
Frazy konkurencji
Bardzo wartościowym źródłem wiedzy na temat słów kluczowych, z którego korzystamy rekomendując architekturę informacji naszym klientom w Takaoto, są frazy konkurencji. Narzędzia takie jak Senuto, Ahrefs, czy Semstorm pozwalają po prostu sprawdzić, na jakie popularne hasła wyświetla się w Google dana domena. Jeśli mamy już rozbudowaną stronę i zastanawiamy się jak ją rozwijać w kontekście SEO, szczególnie cennym podejściem jest analiza content gap. Możesz sprawdzić, na jakie frazy wyświetlają się domeny konkurencji, ale naszej strony nie ma w top50 (czyli zapewne nie posiadamy zindeksowanej strony na ten właśnie temat). 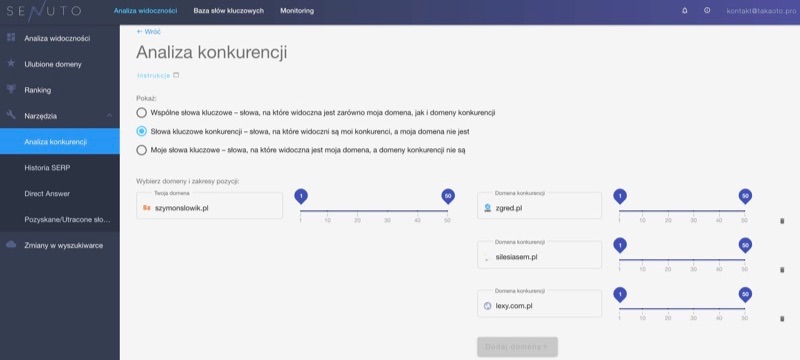 Więcej o doborze i właściwym wykorzystaniu słów kluczowych na stronach docelowych dowiesz się z tego artykułu: Słowa kluczowe i ich rola optymalizacji i pozycjonowaniu stron www na blogu mojej agencji Takaoto.
Więcej o doborze i właściwym wykorzystaniu słów kluczowych na stronach docelowych dowiesz się z tego artykułu: Słowa kluczowe i ich rola optymalizacji i pozycjonowaniu stron www na blogu mojej agencji Takaoto.
Architektura informacji – infografika
Na koniec mam dla ciebie infografikę, która może posłużyć jako wartościowa ściąga. Jeśli chcesz ją gdzieś udostępnić, to dodaj proszę link do https://www.szymonslowik.pl/architektura-informacji-seo/ 